
DevYGwan
NATS JetStream으로 안정적인 보고서 생성 파이프라인 구축하기 본문
저희는 이번에 보고서 생성 로직을 구현했습니다. 저희의 보고서 생성 과정은 대용량 데이터를 조회하고, 이를 LLM 기반으로 분석하여 결과를 도출하는 일련의 절차로 구성됩니다. 이 과정은 DB, FE 서버, BE 서버 등 여러 인프라 자원을 동시에 많이 사용하는 작업입니다. 따라서 다수의 요청이 동시에 발생할 경우, 서버에 과부하가 걸리지 않도록 동시 처리량을 제어할 필요가 있었습니다. 또한, 보고서 생성은 처리 시간이 길고 도중에 실패할 가능성도 존재하기 때문에, 작업이 실패했을 경우 자동 재시작이 가능해야 했으며, 각 요청의 성공 및 실패 여부를 명확히 보장할 수 있는 메커니즘이 필요했습니다.
따라서 정리하자면, 이러한 요구사항을 충족하기 위해 저희가 고려한 사항은 다음과 같습니다.
- 보고서 생성에 많은 리소스가 들어가기 때문에 서버 부하를 막기 위해 한번에 한개씩 순차적으로 처리해야한다.
- 보고서 생성은 실패 시 자동 재시작 등을 통해 안정적으로 완료될 수 있도록 보장해야한다.
- 보고서 상태를 명확하게 관리해야 한다.
이러한 요구사항을 충족하기 위해, 요청을 큐에 적재하고 순차적·제한적으로 처리할 수 있도록 메세지 큐를 도입하였습니다. 이를 통해 안정적으로 리소스를 관리하면서도 장시간 작업의 신뢰성을 확보할 수 있었습니다. 애초에는 별도의 메세지 큐 서버를 두지 않고 처리하려고 했습니다. 인프라 구성이 복잡해지면 그만큼 관리 리소스가 늘어나기 때문입니다. 그러나 프론트엔드나 백엔드 내부에서 단순히 인메모리 큐를 사용하는 방식은 영속성이 보장되지 않아 문제가 있었습니다. 결국 안정성과 확장성을 위해 별도의 메세지 큐 서버를 운영하기로 결정하였고, 여러 후보군을 조사한 끝에 최종적으로 RabbitMQ와 NATS 두 가지로 선택지를 좁혔습니다.
이제, 저희가 최종적으로 어떤 메시지 큐를 선택했는지, 그리고 그 이유에 대해 정리해보겠습니다. 또한, 메세지 큐를 도입해서 어떤식으로 보고서 관련된 처리를 진행했는지 정리해보도록 하겠습니다.
RabbitMQ란?
RabbitMQ는 오랜 기간 사용되어 온 메시지 브로커로, AMQP 프로토콜(Advanced Message Queuing Protocol)을 구현한 시스템입니다. RabbitMQ 아키텍처의 핵심은 프로듀서가 메시지를 익스체인지(exchange)에 발행하면, 익스체인지가 미리 정의된 라우팅 규칙에 따라 메시지를 하나 이상의 큐(queue)로 전달하고, 최종적으로 소비자는 해당 큐를 구독하여 메시지를 받아 처리하는 구조입니다. 기본적으로 Erlang 언어로 되어 있고 전통적인 브로커 아키텍처로 신뢰성 높은 메시지 전달과 다양한 패턴 구현에 적합하며 설정과 관리 면에서 더 많은 기능을 제공하지만, NATS에 비해 운영 오버헤드가 큰 편입니다.
NATS란?
NATS란 대표적인 메세징 시스템 중 하나로, 경량화 & 고성능을 목표로 설계된 오픈소스 메세지 브로커로, Pub/Sub(발행/구독) 패턴을 기본으로 합니다. 별도의 큐 브로커 없이 Subject을 통해 메세지를 발행 & 구독하는 방식이며, 기본 버전인 Core 버전은 메세지를 저장하지 않고 실시간으로 전달합니다. 근본적으로 중앙 브로커의 복잡한 라우팅 없이 동작하는 간결한 구조를 갖고 있어 NATS 서버 자체는 10MB 미만의 매우 가벼운 바이너리 파일로 구현되었고, 설정도 최소화되어 있습니다. 기본 Core 버전이 아닌 jetstream 버전을 쓰면, 메세지 자체를 스트림으로 영속화해 관리할 수 있습니다.
RabbitMQ vs NATS
※ 사용 관점의 차이
| 항목 | NATS JetStream | RabbitMQ |
| 아키텍처 | Go 언어 기반의 메세지 브로커 | Erlang 언어 기반의 메세지 브로커 |
| CPU 사용량 | Low–Moderate 수준으로 매우 효율적 | Erlang VM 위에서 동작하며, 미러 큐·디스크 지속성 활성화 시 CPU 부하가 크게 늘어남 |
| Memory 사용량 | Core NATS는 10–50 MB 정도로 가볍지만, JetStream 활성화 시 100 MB~수 GB까지 소요될 수 있음 | 기본 설정에서 100–500 MB 수준이지만, 큐 백로그나 HA 큐(미러 큐) 사용 시 디스크 + 메모리가 수 GB 단위로 급증 가능 |
※ 운영 관점의 차이
| 항목 | NATS JetStream | RabbitMQ |
| 설치/설정 단순성 | 단일 바이너리 + 최소 config로 설정 가능 | Erlang cookie, PV, plugin 등 다수 설정 필요 |
| 클러스터 관리 | Raft 기반 자동 failover (self-healing) | 미러 큐/Quorum 큐 등 HA 설정 복잡, 상태 동기화 지연 가능 |
| 운영 복잡도 | 낮음 (minimal ops overhead) | 중간~높음 (Erlang 지식 + 다양한 플러그인 관리 필요) |
| 서버 실행 시간 | 빠름 | 상대적으로 느림 |
- 저지연·고성능, 간단한 운영 구조가 중요하면 → NATS JetStream
- 복잡한 라우팅, 다양한 프로토콜 지원, 기업용 안정성을 중시하면 → RabbitMQ
위와 같은 차이가 있습니다. 저희는 메시지 유실 시 재실행으로 처리할 수 있기 때문에 메시지 보존 자체보다는 운영의 효율성과 단순성을 더 중시했습니다. 따라서, 클라우드와 온프레미스 환경 모두에서 빠르고 안정적으로 동작하면서도 관리 부담이 적은 메시지 큐가 필요했기에, 설정이 쉽고 CPU & 메모리 사용량이 효율적인 NATS를 선택했습니다. 또한, 메시지 영속화가 가능하도록 Core가 아닌 JetStream 버전을 도입하기로 결정했습니다.
Nats 서버 설정
신뢰성 있는 작업 큐 설정을 위해 아래와 같은 설정으로 Nats 큐 설정을 진행했습니다.
아래의 설정을 보기 전 간단하게 알아야 할 개념은, stream은 Nats jetstream에서 메세지를 저장/관리하는 단위로 kafka의 "토픽"과 비슷한 개념이며 subject로 발행되는 모든 메세지를 수집합니다.
| 설정 그룹 | 속성 | 설명 | 설정값 |
| Connection | |||
| serverUrl | NATS 서버 접속 URL | nats://localhost:4222 | |
| connectionTimeout | 연결 타임아웃(초) | 5 | |
| reconnectWait | 재접속 대기시간(초) | 2 | |
| maxReconnects | 최대 재접속 시도 횟수 | 10 | |
| Stream | |||
| stream | 생성할 Stream 이름 | job | |
| subject | Stream에 바인딩할 subject | message.process | |
| storageType | 스토리지 타입 | StorageType.File | |
| retentionPolicy | 보관 정책 | RetentionPolicy.WorkQueue | |
| maxAge | 메시지 최대 보관 기간 | 7일 | |
| Consumer | |||
| consumer | Durable Consumer 이름 | job_cons | |
| filterSubject | 구독할 subject 필터 | message.process | |
| deliverPolicy | 전달 정책 (All: 처음부터 전체 전달) | DeliverPolicy.All | |
| ackWait | ACK 대기 시간(초) | 30 | |
| maxAckPending | 최대 미응답 ACK 보류 수 (동시에 처리할 수 있는 메세지 수) | 1 | |
| maxDeliver | 최대 재전달(재시도) 횟수 | 5 | |
| ackPolicy | ACK 정책 (Explicit 명시적 ACK 필요) | AckPolicy.Explicit |
위의 설정 중 주요한 설정은 다음과 같습니다.
- Connection 설정
- 안전한 연결을 위해 서버와의 연결 시도 시 최대 5초동안 연결을 기다린다.
- 만약 연결이 끊기면 2초 후 다시 시도하며, 최대 10번까지 재연결을 시도한다.
- Stream 설정
- 메세지를 메모리가 아닌 디스크 파일(StorageType.File)에 영속적으로 저장한다.
- 메세지가 한 Consumer에게만 전달되면 삭제되는 정책으로 메세지를 관리한다.(RetentionPolicy.WorkQueue)
- 메세지는 최대 7일동안까지만 유효하다. 7일동안 처리되지 않은 메세지는 자동으로 버려진다.
- Consumer 설정
- job_cons 이름을 기준으로 만약 Consumer가 끊겼다가 다시 연결돼도 이어서 메세지 이어서 처리할 수 있다.
- 특정 subject를 가진 메세지(message.process)만 가져와 처리한다.
- stream에 저장된 모든 메세지를 처음부터 전달 받아 처리한다( DeliverPolicy.All)
- NATS 서버가 “WorkQueue 보관 정책”을 사용하는 스트림에서는 DeliverPolicy가 All 외에는 허용되지 않음
- WorkQueue + All 조합은 여러 인스턴스가 한 번만 메시지를 처리해야 할 때(Competing Consumers) 가장 적합함
- Consumer가 메세지를 받고 30초 안에 ACK(완료 응답)을 보내지 않으면 처리 실패로 간주하고 같은 메세지를 다시 보낸다.
- ACK 실패 시 최대 5번까지 재전송한다.
- 메세지를 받으면, 반드시 컨슈머가 ack()을 명시적으로 호출해야 JetStream이 처리 완료로 인정한다.(AckPolicy.Explicit)
이렇게 Nats 서버 설정을 했습니다. 이를 간단하게 요약하자면,
- Connection: 안정적인 연결/재연결 관리
- Stream(job): message.process 메시지를 파일에 저장 (1분 유지, WorkQueue 모드)
- Consumer(job_cons): 처음부터 모든 메시지를 받고, 하나씩 처리하며, ack 기반 재전송 (최대 5번)
이를 통해 메시지 손실을 최대한 방지하고, 중복 처리를 최소화하며, 처리 실패 시 자동 재시도 및 오래된 메시지는 자동 폐기할 수 있게 되었습니다. 결국, 저희는 보고서 생성이라는 리소스 집약적이고 장시간 소요되는 작업을 안정적으로 제어할 수 있었으며, 동시에 작업 상태를 명확히 관리하고 보장할 수 있는 메시지 처리 파이프라인을 구축할 수 있었습니다.
보고서 생성을 위한 아키텍처 설계
이제는 최종적으로 저희가 선택한 보고서 생성을 위한 아키텍처를 설명드리도록 하겠습니다.
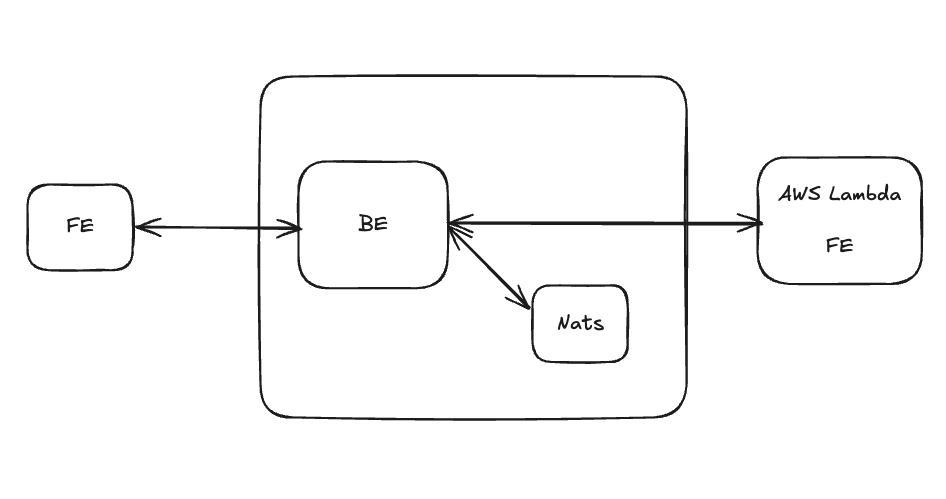
보고서 생성을 위한 아키텍처는 위와 같습니다. 주요한 점은,
- Nats 서버는 퍼블릭 네트워크에 노출되지 않으며, 동일한 VPC/내부 네트워크 상에서 백엔드 서비스만 접근 가능하다.
- 보고서 생성을 위한 별도의 FE 서버가 AWS Lambda을 통해 배포되어있다.
- 보고서 생성 시 Nats 메세지 큐에 작업이 적재되고, 서버는 Nats을 주기적으로 확인해 순차적으로 작업을 처리한다.
입니다.
Nats 서버를 외부로 노출시키지 않는 점은 Nats 메세지 큐에 작업을 퍼블리시 하는 주체는 BE 서버이기 때문입니다. FE에서도 직접 Nats 서버에 메세지를 퍼블리시할 수도 있겠지만 이렇게 한 이유는, 백엔드 서버를 통해 1차적으로 메세지 검증이 이루어질 수 있고 FE에서 굳이 Nats 서버의 정보를 알 필요가 없을 것이라고 생각했기 때문입니다. 그리고 Nats를 외부에 노출시키지 않음으로서, 보안적으로도 더 유리하다고 생각했기 때문입니다.
또한, 위에서 말한 바와 같이 레포트 작성은 많은 리소스가 필요합니다. FE에 요청도 나름 FE서버 내부 Queue통해 한번에 보내는 요청량을 조절하는데, 간단하게만 봐도 Queue에 API 요청이 약 200개가 넘었습니다. (물론 분석하는 데이터 종류가 많으면 300개 넘게도 자주 발생함) 그러다보니 레포트 요청 처리시 FE 서버의 CPU & 메모리 사용량이 급등하는 현상을 확인했습니다.

따라서 같은 FE 서버를 통해 레포트 생성이 이루어진다면, 레포트 생성 요청 처리 중에 다른 요청 처리가 원활하게 처리되지 않을 수 있는 위험이 발생할 수 있었습니다. 따라서, FE 서버를 분리하기로 결정했습니다. 하지만, 별도의 서버를 운영하기에는 보고서 생성 요청이 그렇게 많지 않기 때문에 계속해서 서버를 운영하는 것은 불필요하다고 생각했습니다. 따라서 저희가 선택한 방법은 FE서버를 Lambda로 띄우는 것이였습니다.
FE 서버를 Lambda로 띄울 때의 장점
- 비용 효율성(Cost Efficiency)
- Lambda는 요청이 있을 때만 실행되고 사용한 만큼만 과금된다.
- 저희 같이 레포트 요청 빈도가 높지 않은 상황에서는, 항상 서버를 띄워놓는 방식보다 훨씬 비용을 절감할 수 있다.
- 격리된 실행 환경(Isolated Execution)
- 레포트 작업이 FE 서버와 분리되어 실행되므로, 레포트 처리 중에도 기존 FE 서버가 다른 API 요청을 원활히 처리할 수 있다.
- 즉, 레포트 생성이 서비스의 다른 기능에 영향을 주지 않습니다.
- 운영 부담 감소(Operation Simplicity)
- 별도의 서버를 유지·관리할 필요가 없고, 인프라 관리 부담이 줄어듭니다.
- 장애 대응이나 서버 패치 등 운영 관리 작업을 최소화할 수 있습니다.
이러한 장점으로 AWS Lambda를 통해 별도의 레포트 생성 처리를 위한 FE 서버를 띄웠습니다. 물론 이 과정에서 여러 이슈들이 존재했지만, 이는 다음에 기회가 되면 자세히 설명드리도록 하겠습니다. 간단하게 설명드리자면,
- AWS Lambda에서 쓰는 AWS Key에 관한 권한 처리를 AWS Lambda에서는 별도로 처리해야 한다.
- AWS Lambda에 단순히 FE 서버를 연결하면 빌드 결과물을 S3에 올리고 CloudFront을 얹어서 배포함
- CloudFront의 API 응답 대기 시간은 60초이고 최대 120초이다. -> 보고서 생성 작업으로 쓰긴 부족함...
- 따라서 Lambda Function URL(LFU) 방식을 통해 Lambda 서버가 직접 배포함 -> 최대시간 15분으로 설정 가능
- NEXT_PUBLIC 변수가 아닌 서버 전용 환경 변수는 별도로 AWS Lambda에서 사용하기 위해 넣어줘야됨
등이 있습니다.
이렇게 해서 Nats 설정 및 보고서 생성을 위한 전체적인 아키텍처를 설명드렸습니다. 그렇다면 마지막으로 이를 코드로 어떻게 구현했는지 간단하게 설명드리도록 하겠습니다.
Nats 메세지 Worker 코드
위의 설정을 통해 Nats 설정 및 백엔드 서버(Consumer) 설정은 완료했습니다. 그렇다면 간단하게 코드로 서버가 어떤식으로 메세지를 처리했는지 설명드리도록 하겠습니다. 저희는 Spring Kotlin을 사용하기 때문에 Spring Kotlin 환경을 기준으로 설명드리도록 하겠습니다.
※ Nats 환경 준비
// nats 의존성 build.gradle.kts에 추가
// implementation("io.nats:jnats:2.19.0")
@Configuration
class NatsConfig(
private val properties: NatsConfigProperties,
) {
private val logger = KotlinLogging.logger {}
@Bean
fun natsConnection(): Connection {
//connection 생성 코드
}
@Bean
fun jetStream(connection: Connection): JetStream {
val jsm = connection.jetStreamManagement()
createStream(jsm, properties.stream)
createPullConsumer(jsm, properties.stream, properties.consumer)
return connection.jetStream()
}
private fun createStream(
jsm: JetStreamManagement,
stream: String,
) {
// stream 생성 코드
}
private fun createPullConsumer(
jsm: JetStreamManagement,
stream: String,
consumer: String,
) {
// consumer 생성 코드
}
}서버 실행 시 Nats Jetstream 환경을 준비하는 Configuration 코드입니다. Stream & Consumer가 없으면 생성하고 이후 사용할 JetStream 객체를 초기화해 Spring 컨테이너에 등록하는 코드입니다. Stream & Consumer 생성은 위의 Nats 설정을 기반으로 설정을 했습니다.
즉, JetStream 메세징 환경을 구성한 뒤, JetStream API 핸들러를 앱 전역에서 쓰도록 제공하는 역할을 합니다.
※ 메세지 Publish
@Service
class NatsService(
private val jetStream: JetStream,
) {
private val logger = KotlinLogging.logger {}
fun publishMessage(
subject: String? = "message.process",
message: ObjectNode,
): PublishAck = try {
val msg = NatsMessage.builder()
.subject(subject)
.data(message.toJsonString())
.build()
jetStream.publish(msg)
} catch (e: Exception) {
// 에러 처리
}
}Nats의 메세지 퍼블리시는 위와 같이 간단히 처리했습니다. FE 서버에서 특정 요청이 오면 NatServic의 publishMessage 메서드를 실행해 특정 subject에 특정 메세지를 json 형태로 퍼블리시를 하도록 하는 코드입니다. 여기서 사용하는 JetStream의 경우 위에서 서버 실행 시 Spring 컨테이너에 등록한 JetStream 객체를 사용합니다.
※ 메세지 Subscribe & 처리
@Component
class NatsMessageHandler(
private val jetStream: JetStream,
private val properties: NatsConfigProperties,
) {
private val logger = KotlinLogging.logger {}
@PostConstruct
fun startConsumer() {
logger.info { "Starting NATS pull consumer..." }
val processingExecutor = Executors.newFixedThreadPool(1) { runnable ->
Thread(runnable, "nats-pull-consumer-${Thread.currentThread().name}").apply {
isDaemon = true
}
}
processingExecutor.submit {
startPullingMessages()
}
}
private fun startPullingMessages() {
val pullOpts = PullSubscribeOptions.bind(properties.stream, properties.consumer)
val subscription = jetStream.subscribe(null, pullOpts)
logger.info { "NATS pull consumer started successfully" }
while (!Thread.currentThread().isInterrupted) {
try {
val messages = subscription.fetch(1, Duration.ofSeconds(5))
messages.forEach { message ->
processMessage(message)
}
} catch (e: Exception) {
// 에러 처리
}
}
}
private fun processMessage(message: Message) {
try {
// 로직 처리
message.ack() // 성공 시 명시적으로 message ack 처리
} catch (e: Exception) {
val retryCount = message.metaData().deliveredCount() // 로직 실패 시 retryCount 확인
if (retryCount < 5) {
message.nak() // 5번 미만 시 재시도 처리를 위한 nak 발생
return
}
// 5번 이상 재시도 처리 후에도 실패한 메세지인 경우 ack 발생 후 별도의 알림 발생
message.ack()
}
}
private fun processBusinessLogic(..) {
// 레포트 생성 처리 로직 구현
// AWS Lambda 호출 후 결과 리턴
}
}위의 코드는 Nats JetStream Pull Consumer 설정 코드로 주요 설정은 다음과 같습니다.
- @PostConstruct로 서버 실행 직후 실행했습니다.
- NATS 메시지 구독 루프(fetch → 처리)는 무한 루프라서 메인 스레드를 블로킹하면 안 되기 때문에 별도의 데몬 스레드에서 메세지를 처리하도록 구현했습니다.
- PullSubscribeOptions.bind(...) 를 통해 특정 stream & counsumer로 바인딩해 메세지를 받을 수 있게끔 설정했습니다.
- subscription.fetch(1, Duration.ofSeconds(5))을 통해 서버가 한번에 최대 1개의 메세지를 가져올 수 있게하고 메세지가 없으면 최대 5초동안 대기 후 다시 while 반복문을 통해 다시 메세지를 확인합니다.
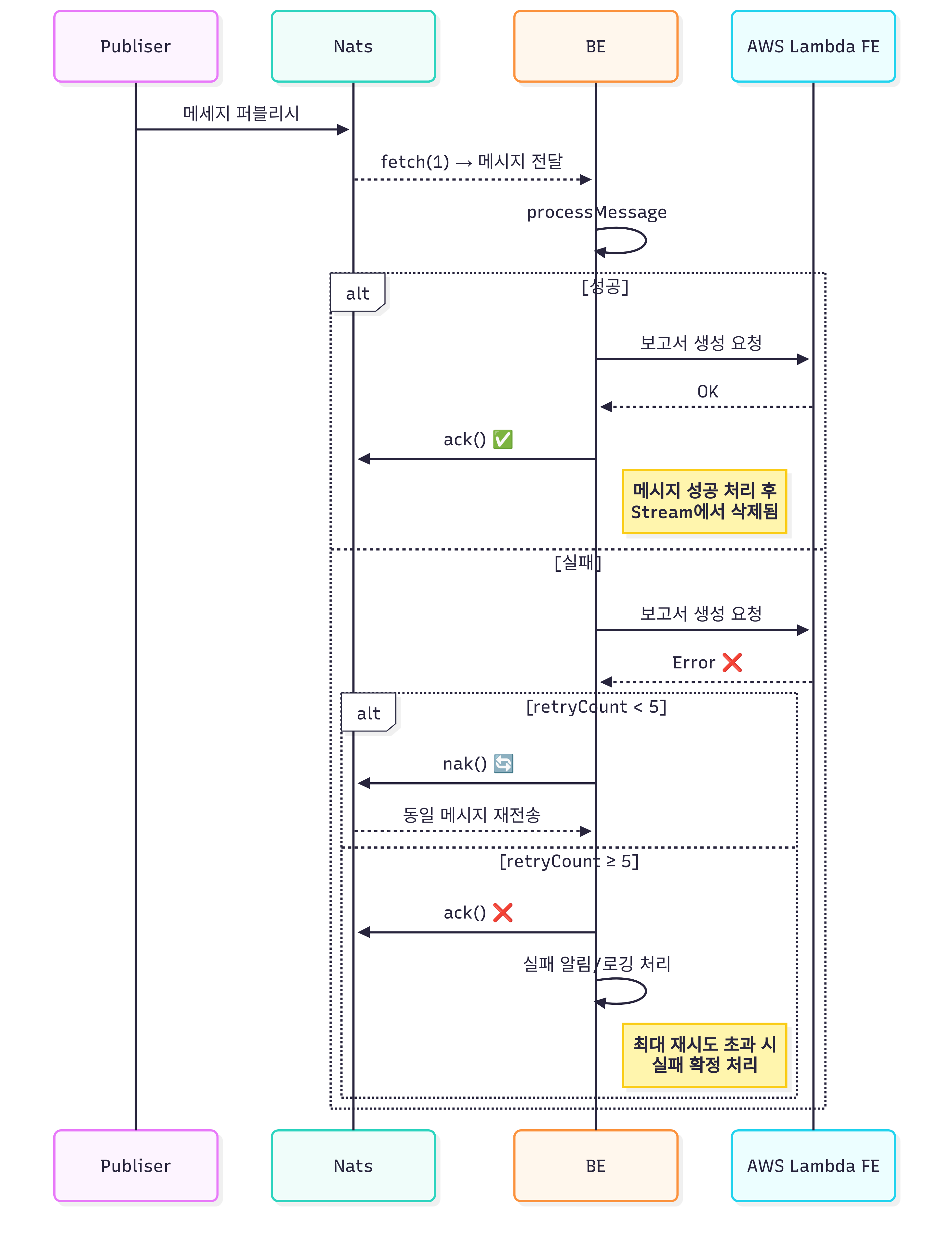
위와 같은 설정으로 서버는 Nats의 메세지를 주기적으로 확인합니다. 그렇다면, 이제는 만약 메세지가 있을 경우 서버가 받아와 어떻게 처리하는지 설명드리도록 하겠습니다.
- 성공 케이스
- 비즈니스 로직 수행 성공 -> 명시적으로 ack() 호출
- JetStream은 ack 메세지를 통해 작업이 완료되었음을 인지하고 해당 메세지를 삭제함
- 실패 케이스
- message.metaData().deliveredCount() → 지금까지 몇 번째 시도인지 확인
- 서버에서 설정한 최대 재시도 횟수(5) 미만이면 nak() 호출 -> JetStream이 같은 메세지를 다시 큐에 넣고 재전송
- 최대 재시도 횟수(5) 이상이면 ack() 호출 후 알림 발생 -> ack() 호출로 인해 JetStream은 더이상 해당 메세지를 추가로 처리하지 않음
이를 도식화하면 아래와 같습니다.
정리
이렇게해서 Nats 메세지 큐를 통한 안정적인 대용량 데이터 보고서 생성 파이프라인 구축을 완료했습니다. 어떻게하면 더 안정적으로 작업을 관리할지 고민하면서 메세지 큐 도입 뿐만 아니라 다양한 인프라 적 요소 & 고려사항이 함께 고려됐던 것 같습니다. 하면서 여러 이슈 사항이 있었지만 다행히... 해결하면서 최종적인 파이프라인을 구축하고 테스트해 어느정도의 안정성을 입증하게 되면서 나름의 뿌듯함도 있었던 작업이였던 것 같습니다.