
DevYGwan
AWS MSK 도입을 통한 실시간 데이터 파이프라인 안정성 확보 본문
저희는 실시간으로 공장에 있는 기기들의 데이터를 수집하고 있습니다. 그러다보니 실시간으로 들어오는 데이터들을 유실 없이 저장해야 합니다. 그래서 저희는 실시간 데이터를 효율적으로 처리하기 위해 아래와 같은 아키텍처를 구현하고 있습니다.

간단하게 순서를 설명드리자면,
1. 공장 기기 → MQTT Broker
- 공장의 각 기기에서 MQTT 프로토콜로 메시지를 발행하며, 이 메시지들은 모두 MQTT Broker로 전달됩니다.
2. MQTT Broker → Kafka Connect → Kafka
- MQTT Broker에 들어온 메시지 중 Kafka에서 처리해야 하는 특정 토픽들은 Kafka Connect의 MQTT Source Connector를 통해 Kafka로 전달됩니다.
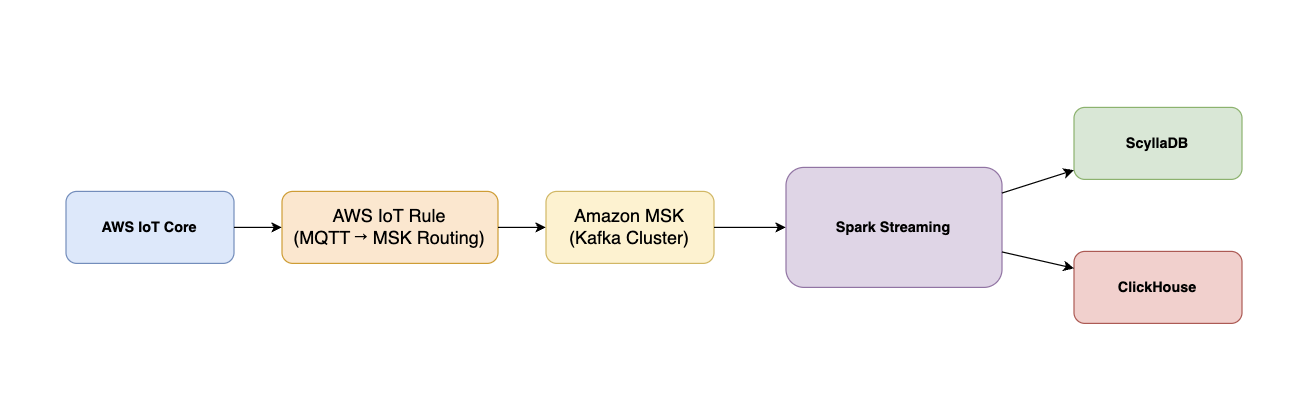
3. Kafka → Spark Streaming → ScyllaDB / ClickHouse
- Kafka로 들어온 메시지는 Spark Streaming이 실시간으로 소비하여 처리하고, 처리된 데이터는 각각의 목적에 따라 ScyllaDB와 ClickHouse에 저장됩니다.
아키텍처는 디바이스에서 발생한 실시간 데이터를 MQTT Broker로 전달하는 것에서 시작됩니다. MQTT Broker에 퍼블리시된 메시지는 Kafka Connect의 MQTT Source Connector가 구독하여 가져오고, 이를 Kafka의 특정 Topic으로 안정적으로 적재합니다. Kafka는 데이터 스트림을 버퍼링하며 Spark Structured Streaming이 이를 실시간으로 소비할 수 있도록 전달하는 중간 허브 역할을 합니다. Spark Structured Streaming은 Kafka에서 데이터를 스트리밍 방식으로 읽어와 필요한 전처리와 변환을 수행한 뒤, 목적에 따라 두 가지 저장소로 데이터를 분기하여 저장합니다. 실시간 조회나 빠른 응답이 필요한 서비스는 ScyllaDB로 저장하고, 대량 분석이나 OLAP 쿼리를 위한 데이터는 ClickHouse로 저장합니다. 이렇게 구성된 전체 파이프라인은 실시간 데이터 수집, 처리, 조회, 분석까지 전 과정이 자동화되고 확장 가능한 형태로 구성되어 있습니다.
이렇듯, 데이터 유실을 최소화하기 위해선 데이터 처리에 필요한 서비스들이 죽지 않고 리소스들이 효율적으로 관리되어야 합니다. 저희는 여기서 사용하는 서비스들을 각각,
- MQTT Broker : AWS IoT Core
- Kafka : EC2 Instance
- Spark : EC2 Instance
- Scylla & Clickhouse : EC2 Instance
을 사용해서 운영하고 있습니다. 아직까지는 사용자가 많지 않아 관리형 서비스 대신 이렇게 직접 운영해서 사용하고 있었습니다. 하지만, 사용자가 늘어나고 관리해야 할 기기들이 늘어나다보니 관리형 서비스를 사용해야 할 필요성을 느끼기 시작했습니다. 그렇다고 무작정 다 관리형 서비스로 바꾸자니, 비용 차이가 커 효율적이지 않았습니다. 그래서 저희가 생각한 기준은
만약 서비스가 죽었을 때 데이터 유실이 발생하는 서비스가 무엇일까?
였습니다. 데이터 유실이 발생하면 저희같은 경우에는 초당 데이터들이 들어오기 때문에 조금만 지나도 많은 데이터가 유실되기 때문입니다. 그래서 이런 서비스의 경우 관리형으로 바꾸는게 장기적인 관점에서도 좋을 것 같다는 생각이 들었습니다.
MQTT Broker의 경우 이미 AWS IoT Core을 쓰고 있기 때문에 제외하고 나머지 후보군,
1. kafka & kafka connect
2. Spark
3. DB
후보 1 : kafka Connect & Kafka
Kafka Connect와 Kafka는 관리형 서비스로 전환했습니다. 그 이유는 MQTT가 메시지를 장기 보관하지 않는 Pub/Sub 전달 시스템이기 때문입니다.
• QoS0은 전달 즉시 메시지가 사라지고
• QoS1/2도 정상 전달 후 삭제되며
• Retain 메시지도 Topic당 1개만 유지됩니다.
따라서 MQTT에서 Kafka로 메시지가 전달되지 않으면 데이터는 금방 유실됩니다. 반면 Kafka는 메시지를 디스크에 로그 형태로 저장하고, retention 정책에 따라서만 삭제되므로 장기 보관이 가능합니다.
이러한 이유로 메시지 저장 안정성을 확보하기 위해 Kafka와 Kafka Connect를 관리형 서비스로 변경했습니다.
후보 2 : Spark
Spark는 관리형 서비스로 변경하지 않았습니다. AWS EMR이 존재하긴 하지만 현재 운영 환경에서는 직접 EC2 위에 Spark를 구성하는 것이 더 적합하다고 판단했습니다. 운영도 큰 문제가 없었고, 원하는 방식으로 유연하게 처리하기에도 비관리형 방식이 더 유리했습니다.
데이터 유실 관점에서도 Spark는 checkpoint를 활용하면 장애 후 재시작 시 처리 지점을 복구할 수 있기 때문에, Kafka만 안정적으로 메시지를 보관한다면 Spark를 관리형으로 전환할 필요성은 낮다고 판단했습니다.
Spark Checkpoint란?
Spark에서 Checkpoint는 스트리밍 애플리케이션이 중단되거나 재시작되더라도 정확한 상태와 진행 위치를 복원할 수 있게 해주는 매우 중요한 안정성 메커니즘입니다. Spark는 체크포인트를 통해 스트리밍 애플리케이션이 어디까지 처리했는지, 어떤 상태를 유지하고 있었는지를 저장해 둬 장애나 재시작이 발생해도 이전 상태에서 이어서 정확하게 처리할 수 있게 해줍니다.
후보 3 : DB
Scylla와 ClickHouse도 관리형 서비스로 전환하지 않았습니다. AWS가 직접 제공하는 관리형 버전은 없지만 유사한 서비스들이 존재하긴 합니다. 그러나 현재까지 운영 과정에서 장애가 발생한 적이 없었고, 관리형 데이터베이스는 비용이 높기 때문에 비용 대비 이점을 얻기 어렵다고 판단했습니다. 현재 요구사항에서는 관리형으로 전환할 필요성이 크지 않았습니다.
결론적으로, 필수적으로 이번에 바꿔야 할 관리형 서비스는
Kafka Connect & Kafka로 결정했습니다.
Kafka & Kafka Connect 관리형 서비스 전환
kafka는 AWS MSK을 사용했습니다. AWS IoT Core와 연결하기 위한 방법을 찾아보던 중, AWS의 공식문서에 해당 방법을 잘 정리해논 링크가 있어 그 링크대로 처리했습니다. 간단하게 제가 어떻게 했는지 순서를 설명드리고 관리형 서비스 전환하면서 중요하게 생각했던 점들을 정리하도록 하겠습니다. 제가 참고한 링크는 아래와 같습니다.
https://aws.amazon.com/ko/blogs/iot/how-to-integrate-aws-iot-core-with-amazon-msk/
How to integrate AWS IoT Core with Amazon MSK | Amazon Web Services
Post by Milo Oostergo, Principal Solutions Architect and Doron Bleiberg, Senior Solution Architect, AWS Startups Introduction Monitoring IoT devices in real time can provide valuable insights that can help you maintain the reliability, availability, and p
aws.amazon.com
※ MSK 클러스터 생성 & AWS IoT Core 연결 설정 순서
- Amazon MSK 클러스터 생성
• VPC 안에 MSK(Kafka) 클러스터를 생성합니다.
• 인증 방식(SASL/SCRAM 등)을 설정합니다. - Secrets Manager에 Kafka 인증 정보 저장
• Kafka에 접속할 사용자 계정/비밀번호를 Secret으로 저장합니다.
• IoT Core에서 사용할 수 있도록 KMS로 암호화된 Secret을 준비합니다.
• Secret 이름은 AmazonMSK_ 접두어 필요. - Secret을 MSK 클러스터에 연동
• 생성한 Secret을 MSK의 인증 정보로 연결(associate)합니다.
• IoT Core가 Kafka로 접근할 때 이 Secret을 사용합니다. - IoT Core가 사용할 IAM Role 생성
• IoT Rule 엔진이 VPC와 MSK에 접근할 수 있도록 IAM Role과 정책을 설정합니다.
• IoT Rule 엔진이 VPC와 MSK에 접근할 수 있도록 IAM Role과 정책을 설정합니다. - IoT Core에서 VPC Destination 생성
• MSK가 존재하는 VPC/Subnet/Security Group을 선택해 IoT → MSK 연결 지점을 생성합니다.
• Kafka bootstrap 서버 주소, 인증 방식(SASL/SCRAM) 설정 - IoT Rule 생성 (MQTT → Kafka 라우팅)
• MQTT Topic에서 받은 메시지를 IoT Rule(SQL)로 필터링한 뒤 → MSK의 특정 Kafka Topic으로 전달하도록 설정합니다.
※ MSK에서 사용한 Security Settings
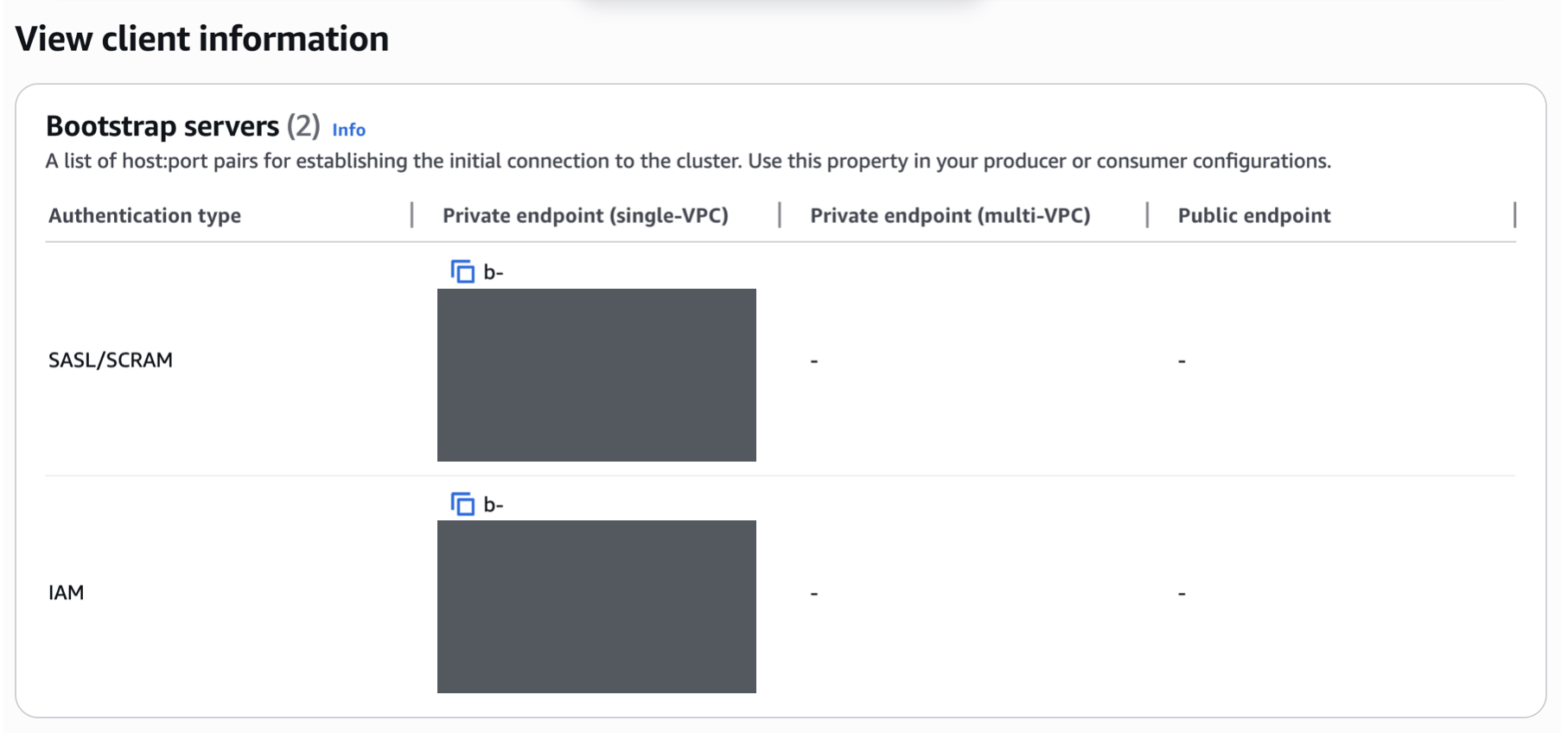
저는 MSK를 사용할 때 사용한 Security Setting은
- Unauthenticated access : disabled
- SASL / SCRAM : enabled
- IAM : enabled
로 설정했습니다. 이렇게 한 이유는 AWS IoT Core는 SASL / SCRAM 방식으로 접근을 허용할 예정이고, 백엔드 서버나, Spark는 IAM 방식으로 접근을 허용할 예정이기 때문입니다. 이렇게 설정하고 나니, 아래와 같이 각각 접근 방식에 따른 url이 별도로 2개씩 생성되었습니다.
※ AWS IoT Rule
여기서 IoT Rule이 Kafka Connect 역할을 대신 해줄 수 있습니다. AWS IoT Rule은 특정 MQTT Topic을 조건에 맞게 필터링한 뒤,
Lambda / Kinesis / S3 / MSK 등 다양한 대상으로 메시지를 라우팅하는 역할을 하기 때문입니다. 물론 Kafka Connect가 더 성능은 좋지만, 저희는 MQTT Message 크기도 최적화하여 그렇게 크지 않고 초당 메세지 수가 수십만 건도 아니기 때문에 운영 편의성을 고려할 때 AWS IoT Rule로도 충분히 처리가 가능하다고 판단했습니다. 따라서 AWS IoT Rule을 통해 Kafka Connect 역할을 대체했습니다.

따라서 이러한 방식으로 Kafka와 Kafka Connect을 관리형 서비스로 변경했습니다.
정리
이번 작업을 통해 실시간 IoT 데이터 파이프라인을 운영하면서 어떤 서비스를 관리형으로 전환해야 안정성을 확보할 수 있는지 면밀히 검토했습니다. 장애 발생 시 어떤 구성 요소에서 실제 데이터 유실이 발생할 가능성이 있는지를 기준으로 관리형 전환 여부를 판단했습니다.
MQTT는 메시지를 장기 보관하지 않는 Pub/Sub 특성상 Kafka로 메시지가 전달되지 않으면 즉시 데이터가 사라집니다. 반면 Kafka는 디스크 기반 로그 저장 방식과 retention 정책을 통해 데이터 유실 없이 장기 보관이 가능하기 때문에, 실시간 파이프라인에서 가장 중요한 안정성 지점을 담당합니다. 이러한 특성을 고려하여 Kafka와 Kafka Connect는 관리형 서비스(MSK)로 전환하여 장애 시에도 안정적으로 메시지를 보관할 수 있도록 했습니다.
Spark는 체크포인트 기능을 통해 장애가 발생해도 처리 상태를 복원할 수 있어, 현재 규모에서는 EC2 기반 자체 운영이 더 유연하고 효율적이라고 판단했습니다. ScyllaDB와 ClickHouse 또한 큰 장애 사례가 없고, 관리형 서비스 비용 대비 이점이 아직 크지 않아 계속 자체 운영하기로 했습니다.
최종적으로, 실시간 데이터의 유실 가능성과 운영 안정성을 기준으로 판단했을 때 이번에 반드시 관리형으로 전환해야 하는 구성 요소는 Kafka와 Kafka Connect였으며, AWS IoT Core와 Amazon MSK를 연동하는 방식으로 안정적인 구조를 구축하게 되었습니다.
물론 전체적으로 관리형 서비스로 전환하면 운영 부담은 줄어들고 안정성은 높아질 수 있지만, 비용이 많이 발생하고 우리가 원하는 방식으로 세부 설정을 적용하기가 어려울 수 있습니다. 따라서 무작정 모든 서비스를 관리형으로 바꾸기보다는, 현재 운영 환경과 장애 발생 시 데이터 유실 가능성, 그리고 비용 대비 효과를 종합적으로 고려해 서비스별로 선택적으로 전환하는 것이 더 적절하다고 판단했습니다. 이렇게 해서 최소한의 비용으로 실시간 데이터 처리를 위한 안정성을 더 확보할 수 있었습니다.
※ 최종적인 구조
'Study > AWS_Service' 카테고리의 다른 글
| Air-Gapped 온프렘 환경에서 Kubernetes Private Registry 구축 (0) | 2025.10.27 |
|---|---|
| AWS IOT를 사용한 MQTT Broker 서버 구축 (0) | 2025.02.17 |
| AWS - WordPress 환경 설정 (5) | 2022.05.15 |
| AWS - S3 (3) | 2022.05.11 |
| AWS - EFS 사용법 (1) | 2022.05.05 |



